
List of Papers and Blog posts

The Thesis Review Episode 44 with Sean Welleck
I had the opportunity to interview with Sean Welleck on his podcast The Thesis Review. We touched on many topics including my personal journey into AI research, and some of my recent research interests such as low-resourcedness and adapting large language models without catastrophic forgetting.
Follow his podcast on his personal website , soundcloud or apple podcasts

Controlling conditional language models without catastrophic forgetting
Tomasz Korbak, Hady Elsahar, German Kruszewski, Marc Dymetman
International Conference on Machine Learning, ICML2022 [paper] [slides] [code]
In this work we target an the important question of how to adapt pre-trained generative models to meet human requirements without destroying their general capabilities ("catastrophic forgetting"). Recent work has proposed to solve this problem by representing task-specific requirements through energy-based models (EBMs) and approximating these EBMs using distributional policy gradients (DPG). Despite its effectiveness, this approach is however limited to unconditional distributions. In this paper, we extend DPG to conditional tasks by proposing Conditional DPG (CDPG). We evaluate CDPG on four different control objectives across three tasks (translation, summarization and code generation) and two pretrained models (T5 and GPT-Neo). Our results show that fine-tuning using CDPG robustly moves these pretrained models closer towards meeting control objectives and — in contrast with baseline approaches — does not result in catastrophic forgetting.

Controlling Conditional Language Models with Distributional Policy Gradients
CtrlGen workshop Neurips 2021 [paper]
Tomasz Korbak, Hady Elsahar, German Kruszewski, Marc Dymetman
Machine learning is shifting towards general-purpose pretrained generative models. However, due to their generic training methodology, these models often fail to meet some of the downstream requirements (e.g. hallucination in abstractive summarization or wrong format in automatic code generation). This raises an important question on how to adapt pre-trained generative models to a new task without destroying its capabilities. Recent work has suggested to solve this problem by representing task-specific requirements through energy-based models (EBMs) and approximating these EBMs using distributional policy gradients (DPG). In this paper, we extend this approach to conditional tasks by proposing Conditional DPG (CDPG). We evaluate CDPG on three different control objectives across two tasks: summarization with T5 and code generation with GPT-Neo.

Sampling from Discrete Energy-Based Models with Quality/Efficiency Trade-offs
CtrlGen workshop Neurips 2021 [paper]
Bryan Eikema, Germán Kruszewski, Hady Elsahar, Marc Dymetman
A new approximate sampling technique, Quasi Rejection Sampling (QRS), that allows for a trade-off between sampling efficiency and sampling quality, while providing explicit convergence bounds and diagnostics. QRS capitalizes on the availability of high-quality global proposal distributions obtained from deep learning models. We demonstrate the effectiveness of QRS sampling for discrete EBMs over text for the tasks of controlled text generation with distributional constraints and paraphrase generation. We show that we can sample from such EBMs with arbitrary precision at the cost of sampling efficiency.

A Podcast on Energy Based Models
This episode of the NAVER LABS Europe podcast series is about Energy-Based Models (EBMs).
These models, based on machine learning, have been around for many years but have been gaining a lot of interest very recently. Podcast guests, research scientist Hady Elsahar and Principal Scientist Marc Dymetman are working on EBMs in the field of natural language. They also co-organized the EBM workshop at the 2021 International Conference on Learning Representations (ICLR).

Energy-Based Models for Code Generation under Compilability Constraints
NLP4prog at ACL2021. [Paper]
Tomasz Korbak, Hady Elsahar, Marc Dymetman, German Kruszewski
In this work, We define an Energy-Based Model (EBM) representing a pre-trained generative model with an imposed constraint of generating only compilable sequences of programming languages. Our proposed approach is able to improve compilability rates without sacrificing the diversity and complexity of the generated samples.

Debiasing large pretrained language models using distributional control
Large Language Models such as GPT3 are trained on large uncurated text from the internet. Despite their huge success and emergent properties such as in-context learning, they suffer a lot from inherent biases and toxicities that could lead to the generation of harmful content. In this blog post, we talk about a novel framework for controlled natural language generation that has been recently published in ICLR2021. Generation with Distributional Control, which achieves great generality on the types of constraints that can be imposed and has a large potential to remedy the problem of bias in language models.

A Distributional Approach To Controlled Text Generation
ICLR2021 ( Oral presentation - top 2.1% )
Muhammad Khalifa* Hady Elsahar* Marc Dymetman*
* first author equal contribution
[Paper] [code] [Blogpost] [Twitter Thread]
We propose a novel approach to Controlled Text Generation, relying on Constraints over Distributions, Information Geometry, and Sampling from Energy-Based Models.

Participatory Research for Low-resourced Machine Translation: A Case Study in African Languages
(∀ ∗ et al.) EMNLP 2020 Findings
[Paper] [Code] [summary]
Research in NLP lacks geographic diversity, and the question of how NLP can be scaled to low-resourced languages has not yet been adequately solved. ‘Low-resourced’-ness is a complex problem going beyond data availability and reflects systemic problems in society. In this paper, we focus on the task of Machine Translation (MT), that plays a crucial role for information accessibility and communication worldwide. Despite immense improvements in MT over the past decade, MT is centered around a few high-resourced languages. As MT researchers cannot solve the problem of low-resourcedness alone, we propose participatory research as a means to involve all necessary agents required in the MT development process. We demonstrate the feasibility and scalability of participatory research with a case study on MT for African languages.
Its implementation leads to a collection of novel translation datasets, MT benchmarks for over 30 languages, with human evaluations for a third of them, and enables participants without formal training to make a unique scientific contribution. Benchmarks, models, data, code, and evaluation results are released at https://github.com/masakhane-io/masakhane-mt.

Self-Supervised and Controlled Multi-Document Opinion Summarization
Hady Elsahar, Maxmin Coavoux, Matthias Gallé, Jos Rozen
EACL2021 [Paper] [Twitter summary]
We address the problem of unsupervised abstractive summarization of collections of user generated reviews with self-supervision and control. We propose a self-supervised setup that considers an individual document as a target summary for a set of similar documents. This setting makes training simpler than previous approaches by relying only on standard log-likelihood loss. We address the problem of hallucinations through the use of control codes, to steer the generation towards more coherent and relevant summaries.Finally, we extend the Transformer architecture to allow for multiple reviews as input.
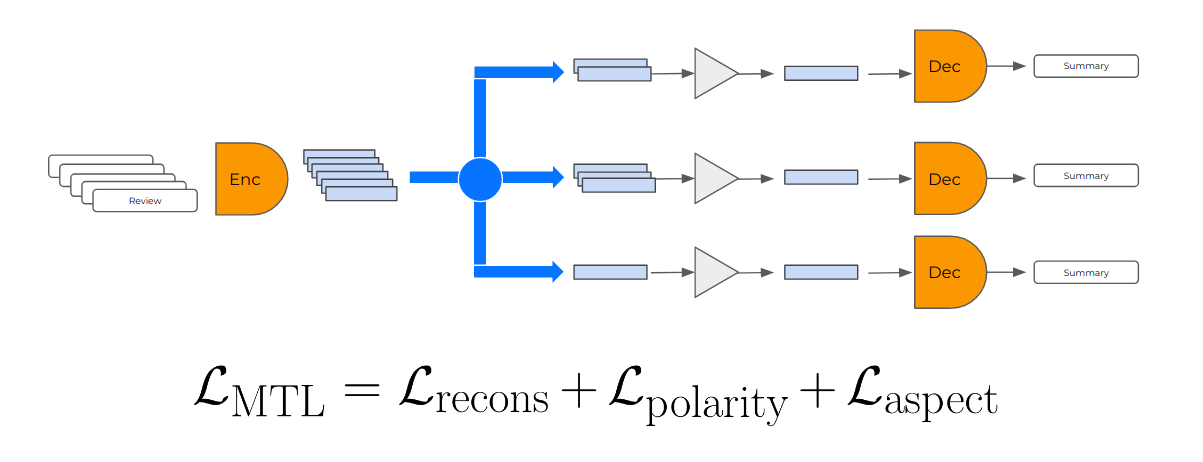
Unsupervised Aspect-Based Abstractive Summarization
User-generated reviews of products or services provide valuable information to customers. However, it is often impossible to read each of the potentially thousands of reviews: it would therefore save valuable time to provide short summaries of their contents. We address opinion summarization, a multi-document summarization task, with an unsupervised abstractive summarization neural system. Our system is based on (i) a language model that is meant to encode reviews to a vector space, and to generate fluent sentences from the same vector space (ii) a clustering step that groups together reviews about the same aspects and allows the system to generate summary sentences focused on these aspects. Our experiments on the Oposum dataset empirically show the importance of the clustering step…
Maxmin Caovoux, Hady Elsahar, Matthias Galle
NEWSUM@EMNLP 2019 [Paper]

Predicting when ML models fail in production
Performance drop due to domain-shift is an endemic problem for NLP models in production. This problem creates an urge to continuously annotate evaluation datasets to measure the expected drop in the model performance which can be prohibitively expensive and slow. In this paper, we study the problem of predicting the performance drop of modern NLP models under domain-shift, in the absence of any target domain labels. We investigate three families of methods (H-divergence, reverse classification accuracy and confidence measures), show how they can be used to predict the performance drop and study their robustness to adversarial domain-shifts.

Scribe: an AI-powered Wikipedia visual editor for under-served Languages
We are happy to announce that the development of Scribe officially started! Scribe is a project funded by the Wikimedia Foundation during the years 2019/2020 to build a tool that aims at helping new editors of under-resourced languages to start writing high-quality articles that confirm with their language standards. Reach out to us, if you are interested in a research collaboration on any of the topics described below.

How do you manage your Machine Learning Experiments?
This blog post aims to raise discussion within the ML research community and propose solutions to find natural, effective & easy to stick to solutions for managing and reproducing your research experiments.

To Annotate or Not? Predicting Performance Drop under Domain Shift
Hady Elsahar, Matthias Galle
NAVER LABS Europe
EMNLP 2019
In this paper, we propose a method that can predict the drop inaccuracy of a model suffering domain-shift with an error rate as little as 2.15% for sentiment analysis and 0.89% for POS tagging
respectively, without needing any labelled examples from the target domain.

Zero-Shot Question Generation from Knowledge Graphs for Unseen Predicates and Entity Types
Hady Elsahar, Christophe Gravier, Frederique Laforest
NAACL2018
We present a neural model for question generation from knowledge graphs triples in a “Zero-shot” setup, that is generating questions for predicate, subject types or object types that were not seen at training time. Our model leverages triples occurrences in the natural language corpus in a encoder-decoder architecture, paired with an original part-of-speech copy action mechanism to generate questions. Benchmark and human evaluation show that our model outperforms state-of-the-art on this task.
[code]

Mind the (Language) Gap: Generation of Multilingual Wikipedia Summaries from Wikidata for ArticlePlaceholders
Lucie-Aimée Kaffee * , Hady Elsahar * , Pavlos Vougiouklis* et al. (* first author equal contrib.)
ESWC2018
We focus on an important support for such summaries: ArticlePlaceholders, a dynamically generated content pages in underserved Wikipedias. They enable native speakers to access existing information in Wikidata. To extend those ArticlePlaceholders, we provide a system, which processes the triples of the KB as they are provided by the ArticlePlaceholder, and generate a comprehensible textual summary. This datadriven approach is employed with the goal of understanding how well it matches the communities’ needs on two underserved languages on the Web: Arabic, a language with a big community with disproportionate access to knowledge online, and Esperanto, an easily-acquainted, artificial language whose Wikipedia content is maintained by a small but devoted community.
[Code]

Learning to Generate Wikipedia Summaries for Underserved Languages from Wikidata
Lucie-Aimée Kaffee * , Hady Elsahar * , Pavlos Vougiouklis* et al. (* first author equal contrib.)
NAACL2018
In this work, we investigate the generation of open domain Wikipedia summaries in underserved languages using structured data from Wikidata. To this end, we propose a neural network architecture equipped with copy actions that learns to generate single-sentence and comprehensible textual summaries from Wikidata triples.
[Code]


Neural Wikipedian: Generating Textual Summaries from Knowledge Base Triples
Pavlos Vougiouklis , Hady Elsahar , Lucie-Aimee Kaffee, et al.
Journal of Web Semantics 2018
We propose an end-to-end trainable system that is able to generate a textual summary given a set of triples as input. The generated summary discusses various aspects of the information encoded within the input triple set. Our approach does not require any hand-engineered templates and can be applied to a great variety of domains. We propose an method of building a loosely aligned dataset of DBpedia and Wikidata triples with Wikipedia summaries in order to satisfy the training requirements of our system. Using these datasets, we have demonstrated that our technique is capable of scaling to domains with vocabularies of over 400k words.