
List of Papers and Blog posts

Writing code for Natural language processing Research
#EMNLP2018 tutorial by Joel Grus, Matt Gardner and Mark Neumann from Allen Institute for Artificial Intelligence
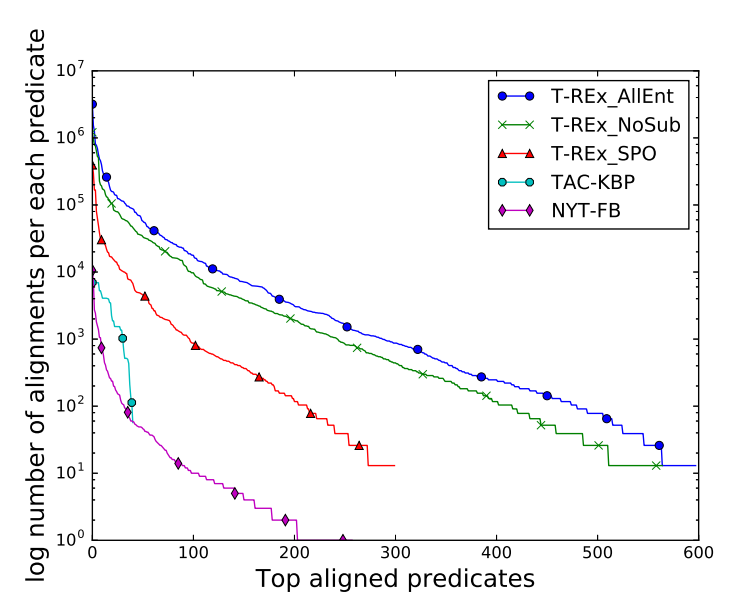
T-REx: A Large Scale Alignment of Natural Language with Knowledge Base Triples
Hady Elsahar, Pavlos Vougiouklis, Arslen Remaci, et al.
LREC2018
In this paper we present T-REx, a dataset of large scale alignments between Wikipedia abstracts and Wikidata triples. T-REx consists of 11 million triples aligned with 3.09 million Wikipedia abstracts (6.2 million sentences). T-REx is two orders of magnitude larger than the largest available alignments dataset and covers 2.5 times more predicates. Additionally, we stress the quality of this language resource thanks to an extensive crowdsourcing evaluation.
[Code] [T-REx Dataset]

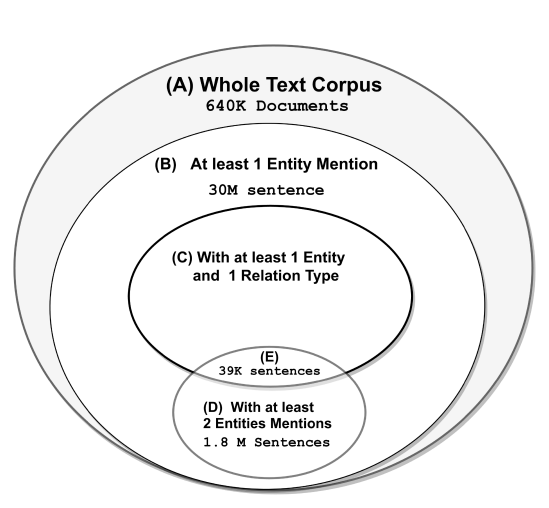
High Recall Open IE for Relation Discovery
Hady Elsahar, Christophe Gravier, Frederique Laforest
IJCNLP 2017
Relation Discovery discovers predicates (relation types) from a text corpus relying on the co-occurrence of two named entities in the same sentence. This is a very narrowing constraint: it represents only a small fraction of all relation mentions in practice. In this paper we propose a high recall approach for Open IE, which enables covering up to 16 times more sentences in a large corpus. Comparison against OpenIE systems shows that our proposed approach achieves 28% improvement over the highest recall OpenIE system and 6% improvement in precision than the same system.
Building Large Arabic Multi-domain Resources for Sentiment Analysis
Hady Elsahar, Samhaa R. El-Beltagy
CICLing2015 [Best Paper Award]
While there has been a recent progress in the area of Arabic Sentiment Analysis, most of the resources in this area are either of limited size, domain specific or not publicly available. In this paper, we address this problem by generating large multi-domain datasets for Sentiment Analysis in Arabic. The datasets were scrapped from different reviewing websites and consist of a total of 33K annotated reviews for movies, hotels, restaurants and products. Moreover we build multi-domain lexicons from the generated datasets. Different experiments have been carried out to validate the usefulness of the datasets and the generated lexicons for the task of sentiment classification. From the experimental results, we highlight some useful insights addressing: the best performing classifiers and feature representation methods, the effect of introducing lexicon based features and factors affecting the accuracy of sentiment classification in general. All the datasets, experiments code and results have been made publicly available for scientific purposes.
[Code & Datasets]